Implementation of Machine Learning Algorithm for Sentiment Analysis Of Presidential Election
In 2019, citizens of Indonesia participated in the democratic process of electing a new president, vice president, and various legislative candidates for the country. The 2019 Indonesian presidential election was very tense in terms of the candidates' campaigns in cyberspace, especially on social media sites such as Facebook, Twitter, Instagram, Google+, Tumblr, LinkedIn, etc. The Indonesian people used social media platforms to express their positive, neutral, and also negative opinions on the respective presidential candidates.
The campaigning of respective social media users on their choice of candidates for regents, governors, and legislative positions up to presidential candidates was conducted via the internet and online media. Therefore, the aim of this paper is to conduct sentiment analysis on the candidates in the 2019 Indonesia presidential election based on Twitter datasets. The study used datasets on the opinions expressed by the Indonesian people available on Twitter with the hashtags (#) containing "Jokowi and Prabowo."
We conducted data pre-processing using a selection of comments, data cleansing, text parsing, sentence normalization, and tokenization based on the given text in the Indonesian language, determination of class attributes, and, finally, we classified the Twitter posts with the hashtags (#) using Naïve Bayes Classifier (NBC) and a Support Vector Machine (SVM) to achieve an optimal and maximum optimization accuracy.
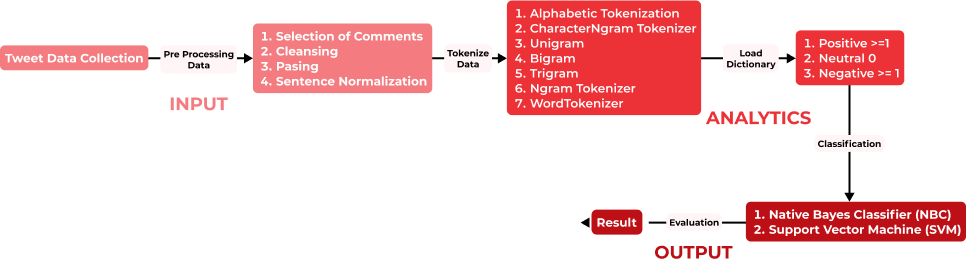
Machine learning in action
Here, we train an ML model to recognize the sentiment based on the words and their order using a sentiment-labeled training set. This approach depends largely on the type of algorithm and the quality of the training data used. The sentiment analysis revealed that there was much negative public sentiment on Twitter aimed at the 2019 Indonesian presidential candidates.
The greatest accuracy value was obtained when using a combination of the SVM machine learning algorithm and alphabetic tokenization, which yielded an accuracy value of 79.02%. The lowest accuracy value in this study was obtained for the NBC machine learning algorithm with N-gram tokenization, which had an accuracy value of 44.94%. This study has therefore demonstrated that the SVM machine learning algorithm produces higher accuracy compared to the NBC machine learning algorithm.