Introduction
Streaming data is the continuous flow of information from disparate sources to a destination for real-time processing and analytics. It is becoming a core component of enterprise data architecture due to the explosive growth of data from non-traditional sources such as IoT sensors, security logs, and web applications.
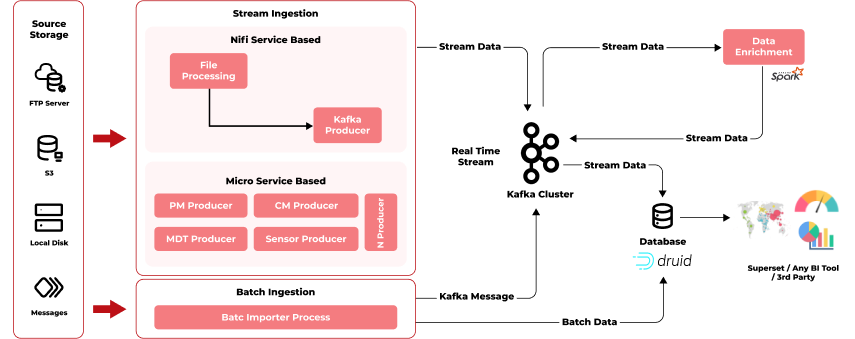
Before data can be used for analysis, the destination system has to understand what the data is and how to use it. Data flows through a series of zones with different requirements and functions.
Overview
In the Digital Transformation era, organizations have an ever-growing tremendous of real-time data, distributed across numerous data sources. Data has a format that requires real-time processing, storage, integration, and analytics at ultra-low latency. A streaming-based application like sharing application, stock trading platform, social network, and Internet of Things all require real-data streams, and this data continues to grow in volume and complexity.
By leveraging data streaming platform, business are discovering that they can create new business opprtunities, strengthen their competitive advantage, make their existing operations more efficient, and open new use cases while reducing operational burden and complexity.
Stream Data Explained
Streaming data is the continuous flow of data generated by various sources. By using stream processing technology, data streams can be processed, stored, analyzed, and acted upon as it's generated in real-time.
Stream Data Benefit
Data collection is only one piece of the puzzle. Today's enterprise businesses simply cannot wait for data to be processed in batch form. Instead, everything from fraud detection and stock market platforms to rideshare apps and e-commerce websites relies on real-time data streams.
Paired with streaming data, applications evolve to not only integrate data, but process, filter, analyze, and react to that data in real-time, as it's received.
In short, any industry that deals with big data that can benefit from continuous, real-time data will benefit from this technology.